
Clinical diagnostics is undergoing a fundamental shift. As genomics
becomes embedded in oncology, rare disease diagnosis, pharmacogenomics, and inherited condition
screening, the central challenge is no longer whether genomic data can be generated. It is whether that
data can be operationalized reliably, integrated into clinical systems, and sustained under regulatory
scrutiny at scale.
Genomics data engineering services play a decisive role in this
transition. They sit between sequencing technologies,
bioinformatics pipelines, clinical
interpretation workflows, and downstream systems such as LIMS, EHRs, and reporting platforms. When this
layer is weak or fragmented, clinical diagnostics platforms struggle to scale, reproduce results, or
meet compliance expectations, regardless of scientific sophistication.
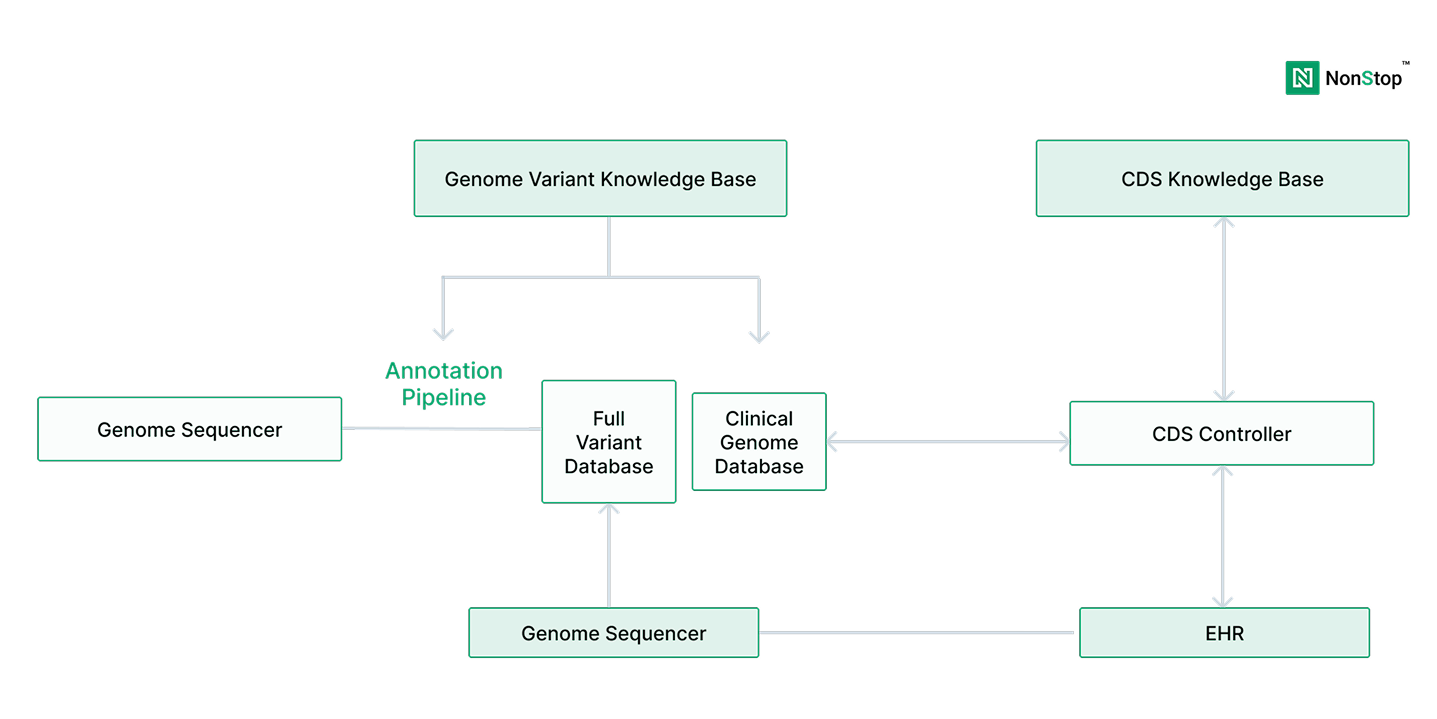
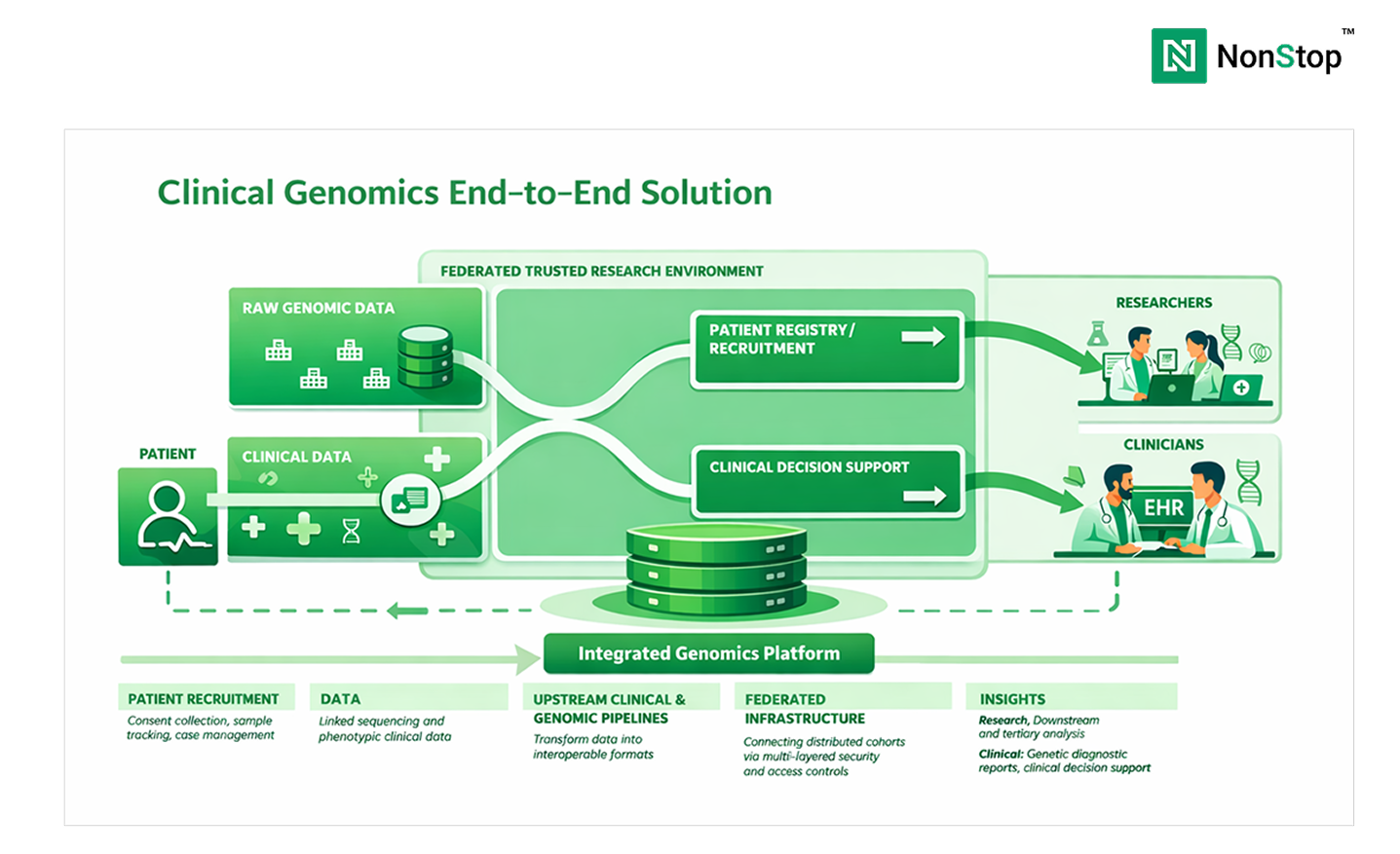
Why Genomics Data Engineering Has Become Central to Clinical Diagnostics
According to the National Human Genome Research Institute (NHGRI), the cost of sequencing a human genome
has fallen from over $100 million in the early 2000s to under $1,000 today. As a result, genomic
sequencing has moved from research settings into routine clinical diagnostics.
However,
sequencing alone does not deliver clinical value. Diagnostics organizations depend on interpretation,
traceability, reproducibility, and integration with care workflows. These requirements are not solved by
faster sequencers or better variant callers - they are solved by platforms.
Research published in Nature Genetics and The New England Journal of Medicine repeatedly highlights a
consistent gap: while variant detection accuracy has improved significantly, many labs struggle with
longitudinal data reuse, interpretation consistency, and audit-ready workflows.
Genomics
data engineering services address this gap by transforming analytical outputs into durable clinical
systems.
From Bioinformatics Pipelines to Clinical Data Platforms
A common mistake in diagnostics organizations is assuming that robust bioinformatics pipelines equate to
production readiness. They do not.
Bioinformatics pipelines
are designed to answer analytical questions, including variant calling, annotation, filtering, and
prioritization. Clinical diagnostics platforms must answer operational ones.A common misconception is
that production readiness depends primarily on selecting the right tools - a workflow engine, a data
warehouse, or an AI framework.
A production-grade genomics data platform must support:
- Standardized genomic and clinical data models
- Versioned reference datasets and interpretation logic
- Lineage tracking across every pipeline execution
- Repeatable re-analysis as evidence evolves
- Integration with LIMS and EHRs using HL7 and SMART on FHIR
- Monitoring, retries, and failure recovery
- Auditability for regulatory review
Without this foundation, pipelines remain fragile, even when they produce accurate results.
Many diagnostics teams realize too late that scaling clinical genomics is less about adding new
workflows and more about stabilizing the platform underneath them.
Talk to our Platform Experts
The Data Reality Behind Modern Genomics Diagnostics
Genomic data is uniquely demanding in both scale and longevity. A single whole-genome sequence typically
produces 100–200 GB of raw and intermediate data, depending on coverage and pipeline design.
At the clinical scale, programs quickly accumulate petabytes of data, even before accounting
for annotations, derived features, and repeated re-analysis.Re-analysis is not an edge case. The
American College of Medical Genetics and Genomics (ACMG) has documented that variant classifications
change over time as evidence evolves.
This makes reproducibility, lineage, and version
control clinical requirements, not optional enhancements.Without strong genomics data engineering:
- Historical data becomes underutilized
- Re-analysis becomes slow and expensive
- Institutional knowledge fails to compound
- Technical debt grows quietly
Production-ready platforms treat genomic and clinical data as long-lived assets, not transient outputs.
Why Clinical Diagnostics Platforms Break Under Scale
Early genomics diagnostics initiatives often succeed. Pipelines run.
Reports are delivered.
Stakeholders gain confidence.But when these initiatives are expected to run continuously, supporting
targeted clinical programs, scaling across defined patient populations, and operating under regulatory
scrutiny, structural weaknesses begin to surface.
1. Definition of PICOS:
- Patients
- Interventions
- Outcomes
- Comparisons
2. Precise localization of clinical problem:
- Clinical practice steps: diagnosis, treatment, care, etc.
- Clinical perspective: different areas of expertise
- Patient perspective: quality of life
1. Source of data system
- Structured medical tests
- Non-structured natural language, text
2. Data deduplication
3. Data evaluation
- The Randomization of missing data
1. Assessment of impact of missing value/imputation
2. Data transformation
- Variable or outcome transformation
3. Data standardization
1. Clinical significance of features
2. Distribution of features
3. Contribution of the feature to the outcome
4. Method of feature selection
- Logistic regression
- Random forest
- Mean accuracy reduction
- Recursive feature elimination, etc.
1. Determining the optimal model metrics
- Sample imbalance
- Outcome diversity
- Multiple outcomes with different weights
2. Model training
- Single model
- Mixed model
3. Method for model selection
- Logistic regression
- Random forest
- Support vector machines
1. Accuracy of model
- ROC
2. Clinical significance
- DCA
- Meets the software and hardware operating environment
- Seamless integration with existing clinical information
- Continuous model upgrading
Common failure modes include:
- Pipelines that cannot be rerun reliably months later
- Brittle schema-dependent integrations
- Audit gaps that emerge during compliance reviews
- Rising dependence on individual engineers to keep systems running
- Increasing turnaround times as volume grows
Across healthcare and life sciences, studies consistently show that 60–70% of data and AI initiatives
fail to reach sustained production use, with primary causes tied to data readiness, governance, and
operational complexity rather than analytical quality.
At this stage, the issue becomes a
leadership concern, rooted in platform design, ownership, and long-term strategy.
Cost, Scale, and the FinOps Reality in Genomics Platforms
Cloud cost is one of the least predictable aspects of scaling diagnostics platforms. FinOps Foundation
guidance and large-scale cloud architecture studies show that, in data-intensive platforms, compute is
often not the dominant long-term cost driver.
Instead, storage growth, retries, inefficient
orchestration, and data movement can account for 30–50% of total platform cost over time.
While
spot or preemptible compute can reduce raw compute costs by 70–90%, these savings only materialize when
pipelines are engineered for failure tolerance, observability, and reproducibility.
AI in Clinical Diagnostics Depends on Data Engineering Maturity
AI is increasingly central to clinical diagnostics strategies, but operational success remains
limited. Gartner and McKinsey report that only 20–30% of AI initiatives reach sustained production
use across industries.
In healthcare and genomics, the blockers are rarely model
accuracy. They are operational:
Regulatory guidance increasingly emphasizes traceability and defensibility for AI-assisted decision
support. Without production-grade data engineering, AI outputs remain difficult to trust and even
harder to scale responsibly.
Genomics
data engineering provides the foundation that AI systems depend on.
A Decision Framework for Leaders Evaluating Genomics Data Engineering Readiness
Before scaling clinical diagnostics platforms, leaders should pressure-test readiness across five
dimensions:
- Data Models – Are genomic and clinical data standardized and versioned?
- Pipeline Reproducibility – Can results be reproduced months or years later?
- Governance & Lineage – Is every transformation auditable and traceable?
- Integration – Do systems interoperate cleanly with LIMS and EHRs?
- Operational Ownership – Is accountability clear for cost, reliability, and evolution?
Gaps in any of these areas tend to surface later as cost overruns, compliance risk, or operational
fragility.
Where NonStop Fits
Organizations typically engage NonStop when genomics diagnostics programs reach a critical inflection
point, when early analytical success must become dependable clinical operations.
NonStop
works as an engineering and platform partner, helping teams:
- Convert fragmented pipelines into governed systems
- Design reproducible, auditable interpretation workflows
- Integrate genomics and clinical data at scale
- Prepare platforms for AI and regulatory scrutiny
- Build long-term architectures that remain adaptable
The focus is not on replacing scientific expertise. It is on building systems that allow that expertise
to operate reliably over time.
Outcomes: What Strong Genomics Data Engineering Enables
When genomics data engineering is done well, diagnostics organizations consistently achieve:
- Faster and more predictable turnaround times
- Reproducible results across time and cohorts
- Lower operational risk during audits and reviews
- Controlled cloud costs as volume grows
- Platforms that support future diagnostics and AI initiatives
These outcomes compound over time, creating a durable operational advantage.
What Decision-Makers Should Do Next
Building a modern clinical diagnostics platform is not a tooling decision. It is a systems and
governance decision with long-term consequences.
The organizations that succeed are those
that:
- Invest early in data engineering foundations
- Treat genomics data as a long-lived clinical asset
- Design for reproducibility, not just performance
- Align platform architecture with regulatory reality
The strategic question is no longer whether genomics will shape clinical diagnostics. It is whether the
platform supporting it is built to scale responsibly, operate predictably, and earn trust under
pressure.
If your diagnostic platform is approaching that inflection point, a focused, pratical discussion can
often clarify where operational risk and cost are likely to surface next and what to address before
scale makes change far more expensive.
Talk to our Experts