
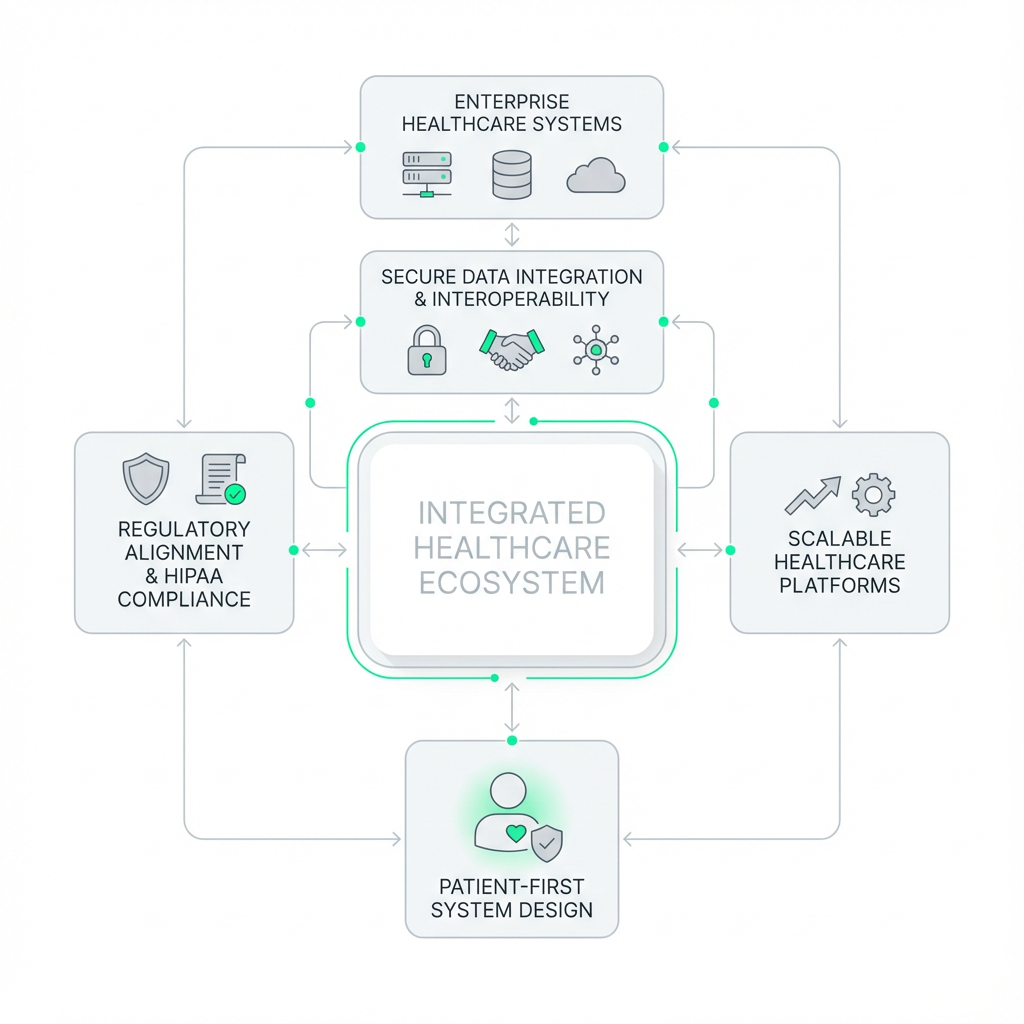
Legacy systems blocking interoperability
Outdated healthcare IT systems that cannot exchange data with modern EHRs, payors, or lab platforms, creating care gaps and compliance exposure.

Fragmented EHR and payor integrations
Clinical, billing, and claims workflows running on disconnected systems, with no unified data layer and no reliable HL7 or FHIR interoperability between platforms.

Compliance gaps across HIPAA, SOC2, GDPR
Healthcare platforms built fast without compliance by design, accumulating audit risk, security debt, and regulatory exposure that compounds at scale.

Clinical data locked in siloed systems
Patient records, claims data, lab results, and device outputs spread across systems with no governed analytics layer, making population health management and clinical decision support impossible.




Hospitals & Health Systems
EHR platforms, interoperability solutions, clinical workflow systems, and HIPAA-compliant software development for US healthcare IT modernization, designed to support care delivery at scale.

Payors & Insurers
Claims management, prior authorization automation software, fraud detection, and healthcare analytics dashboard development, improving efficiency and compliance across payor operations.

Life Sciences, Pharma & Genomics
Clinical trial management software development, LIMS development for genetic testing laboratory environments, and clinical genomics platform development for precision medicine, connecting research and clinical delivery.

HealthTech Startups & Medical Devices
MVPs, healthcare SaaS development, AI-powered digital health products, medical device software development, and ISO 13485 compliant medical software, built for regulated markets from Day 1 with a SOC2 HIPAA compliant health tech outsourcing partner.





Genetics & Precision Medicine Enablement
Engineering platforms for genomic data management, sample tracking, bioinformatics pipeline execution, and AI-driven personalized care insights, from LIMS to clinical report delivery.





Building a Scalable Employee Wellness Platform
Health Improvement Solutions (HIS)
Challenge
HIS needed a scalable, user-friendly SaaS platform to deliver health assessments and coaching programs globally while increasing engagement and adoption of preventive healthcare practices.
Impact
- Scalable SaaS platform supporting global wellness programs
- Seamless connectivity between wellness experts and individuals
- Improved engagement and adoption of preventive healthcare practices

Enabling Smarter Healthcare Strategies with Real-Time Analytics
US based Healthcare Analytics & Consultancy Provider
Challenge
- Fragmented data and lack of unified population health metrics
- Manual reporting slowed down health strategy design
- Needed scalable teams based on business priorities
Impact
- Centralized dashboard for employers and insurers
- Real-time insights for healthcare strategy design
- Improved reporting and decision-making efficiency
Transforming Wearable Health Tech with AI-Powered Stress Management
BreathAI (AI Wellness Assistant)
Challenge
- Deliver personalized, AI-driven interventions for stress and wellness.
- Ensure solutions were non-intrusive and user-friendly.
- Maintain strict ISO 13485 compliance as medical device software.
Impact
- Enhanced device value with AI-driven personalization and GenAI-powered recommendations.
- Boosted user engagement with tailored interventions for stress management.
- Maintained ISO 13485 compliance, ensuring medical-grade reliability and safety.
Modernizing Health Screening Data Management for a US Wellness Provider
US based Health Screening & Wellness Services Provider
Challenge
- Outdated Technology → Legacy platform slowed performance and lacked scalability.
- Compliance Risks → Maintaining strict HIPAA and HL7 standards was becoming difficult.
- Business Continuity Concerns → Migration had to be seamless to avoid disruption of live screening programs.
Impact
- Modernized legacy systems with a future-ready, scalable technology stack and enhanced end-user experience.
- Ensured compliance with HIPAA and HL7, reducing regulatory risks.
- Maintained business continuity with a cost-efficient, non-disruptive transition.
10x Faster Healthcare Data Analytics with Scalable Big Data Engineering
nClasser
Challenge
Traditional off-the-shelf tools could not scale for large-volume healthcare entity analytics, leading to performance bottlenecks, high infrastructure costs, and limited scalability.
Impact
- 10x faster entity analytics compared to COTS products
- Lower infrastructure costs with cost-optimized clusters
- HIPAA-compliant, scalable healthcare data analytics platform
NonStop Builds a Secure, Integrated Health Delivery Platform for a US Care Provider
US based Hospitalization & Care Provider Platform
Challenge
- Fragmented Communication and legacy tool No secure, real-time messaging between healthcare teams.
- Inefficient Patient Management and lack of Interoperability preventing a comprehensive patient view, treatment history and medication schedules.
- Compliance Risks – Ensuring HIPAA-compliant communication was a growing concern.
Impact
- Streamlined Care Delivery with centralized patient management.
- Improved Collaboration through HIPAA-compliant, secure messaging.
- Seamless Interoperability with existing EHR and hospital systems.
Building a Global SaaS Platform for Health & Wellness Coaching
HIS (US based Wellness Provider)
Challenge
HIS needed a scalable, user-friendly SaaS platform to deliver health assessments and coaching programs globally while increasing engagement and adoption of preventive healthcare practices.
Impact
- Scalable SaaS platform supporting global wellness programs
- Seamless connectivity between wellness experts and individuals
- Improved engagement and adoption of preventive healthcare practices
Population Health Management: Enabling Smarter Healthcare Strategies with Real-Time Analytics
US based Healthcare Analytics & Consultancy Provider
Challenge
- Fragmented data and lack of unified population health metrics
- Manual reporting slowed down health strategy design
- Needed scalable teams based on business priorities
Impact
- Provided a centralized and intuitive dashboard for employers and insurers.
- Empowered stakeholders with real-time insights for effective healthcare strategy design.
- Improved efficiency and decision-making with ad-hoc query and reporting tools.












