

The global bioinformatics market generated $8,614.29 million in 2019 and is projected to reach $24,731.61 million by 2027, growing at a CAGR of 13.4% from 2020 to 2027 (source).
Yet despite this growth, most organisations stumble on a far more basic problem. Not how to design algorithms. Not how to analyse data. But how to run their computational workflows reliably in production?
This gap between analysis and execution is where most bioinformatics efforts quietly struggle, and where real business impact is either created or lost.
Let us start by understanding why this deployment problem exists, especially in the era of cloud computing. The root of the issue often lies in how we define workflows and pipelines in bioinformatics.
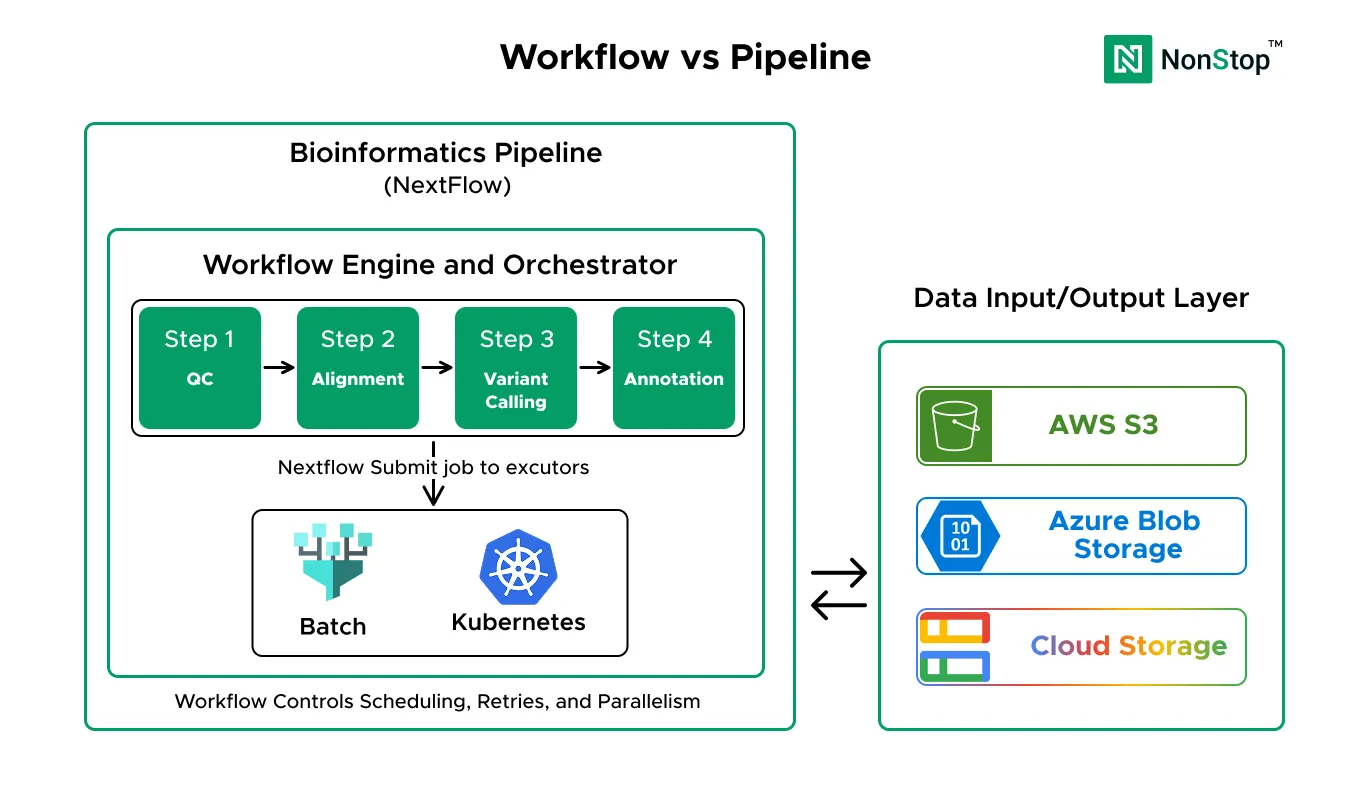
A workflow is the computational logic. It’s the executable definition of what runs, in what order, and how data flows between steps. This is what you write in Nextflow, WDL, Snakemake, or CWL. It bundles tools into processes, connects them with data channels, and defines the DAG for execution. A workflow answers one question clearly: what computation happens?
A pipeline is the full operational system that turns raw data into a usable result, reliably and repeatedly, under real-world constraints. It includes the workflow, but also everything around it: reference databases, storage architecture, compute infrastructure, security controls, access management, monitoring, cost controls, retries, audits, and operational ownership. A pipeline answers a different question: can we trust this to run in production?
The relationship is simple but critical. The workflow is a major component of the pipeline, but it is not the pipeline by itself.
Four converging trends are forcing bioinformatics teams to professionalize their infrastructure:
Before choosing an approach, assess two key factors:
These two factors determine which option fits best.

AWS HealthOmics is a purpose-built, fully managed service for genomics and multiomics workloads. It provides storage, analytics, and workflow execution specifically designed for healthcare and life sciences.
Managed By: AWS (fully managed service)
HealthOmics removes infrastructure complexity entirely. You focus on workflows, AWS handles everything else: compute provisioning, scaling, security, compliance controls, and monitoring.
At small to medium scale (under 5,000 samples/month), the total cost is competitive because you save on personnel. At a very large scale, per-sample costs become the dominant factor.
While AWS HealthOmics is designed for healthcare workloads, using cloud storage for PHI (Protected Health Information) requires specific HIPAA compliance measures
Batch computing services (AWS Batch, Azure Batch, Google Cloud Batch) are managed services that run batch jobs at any scale. Combined with Nextflow, they enable production-grade workflow execution without requiring infrastructure management.
Managed By: Partially managed (cloud provider handles compute scaling, you manage workflow orchestration)
Batch services provide the simplest path to production-grade pipelines. No server management, automatic scaling, pay only for compute time used. You get reliability without complexity.
Using spot instances reduces compute costs by up to 90%. At medium scale (100–5,000 samples/month), this is typically the most cost-effective option overall.
If handling Protected Health Information, batch services require manual HIPAA compliance configuration
Kubernetes is a container orchestration platform that provides maximum control over infrastructure. Running Nextflow on Kubernetes (Amazon EKS, Azure AKS, Google GKE) provides the flexibility to customise every aspect.
Managed By: Partially managed (cloud provider manages Kubernetes control plane, you manage most other aspects)
Kubernetes provides maximum flexibility and control. If you have complex requirements, need advanced features, or already have Kubernetes expertise, this gives you the power to build exactly what you need.
The infrastructure is cost-efficient, but you need personnel to manage it. At small to medium scale, the team cost outweighs infrastructure savings. At very large scale (10,000+ samples/month), infrastructure optimization makes this cost-competitive overall.
Kubernetes provides the most control over compliance but also the most responsibility.
Dime
nsion
AWS Health
Omics
Batch Services
Kubernetes
Best
For
Clinical diagno
stics, comp
liance-first
Resear
ch labs, cost-efficient opera
tions
Enter
prise with Dev
Ops capa
bility
Setup Time
Quick
Fast
Longer
Time to Produ
ction
Very Fast
Fast
Signif
icant invest
ment
Team Needs
Bioinfor
matics + Basic Cloud
Bioinfo
matics + Cloud Expertise
Dedi
cated DevO
ps exper
tise
Opera
tional Burde
n
Very Low
Low
High
Infrast
ruc
ture Cost
Highest Per Sample
Lowest (with spot)
Comp
etitive at large scale
Opera
tional Cost
Lowest (minimal staff)
Moderate
Highest (requires team)
HIPAA Compl
iance
Built-in guidance
Manual configu
ration
Full manual configu
ration
Custom
ization
Limited
Moder
ate
Maximum
Multi-Cloud
AWS only
Cloud-specific
Portable every
where
Learning Curve
Low
Low to Moderate
Steep
Choose based on your situation:
Clinical diagnostics, need HIPAA compliance, limited IT team.
Research labs, cost-sensitive, small to medium scale.
Enterprise with a DevOps team needs advanced customization, large scale.
The bioinformatics infrastructure market is growing at 13% annually, reaching $18.7 billion by 2027. Organizations that choose infrastructure wisely gain a competitive advantage through faster results, lower costs, and better reliability. Those who choose poorly waste money on over-engineered solutions or face scaling problems later.